














A Rough Approximation
A friend on social media recently asked for some help translating an image of an ultrasound into audio. She had a printout from when she had a fetal ultrasound taken, but had no recording of the audio she heard produced by the ultrasound machine. Luckily she was able to provide me with a nice scan of the printout to work with.
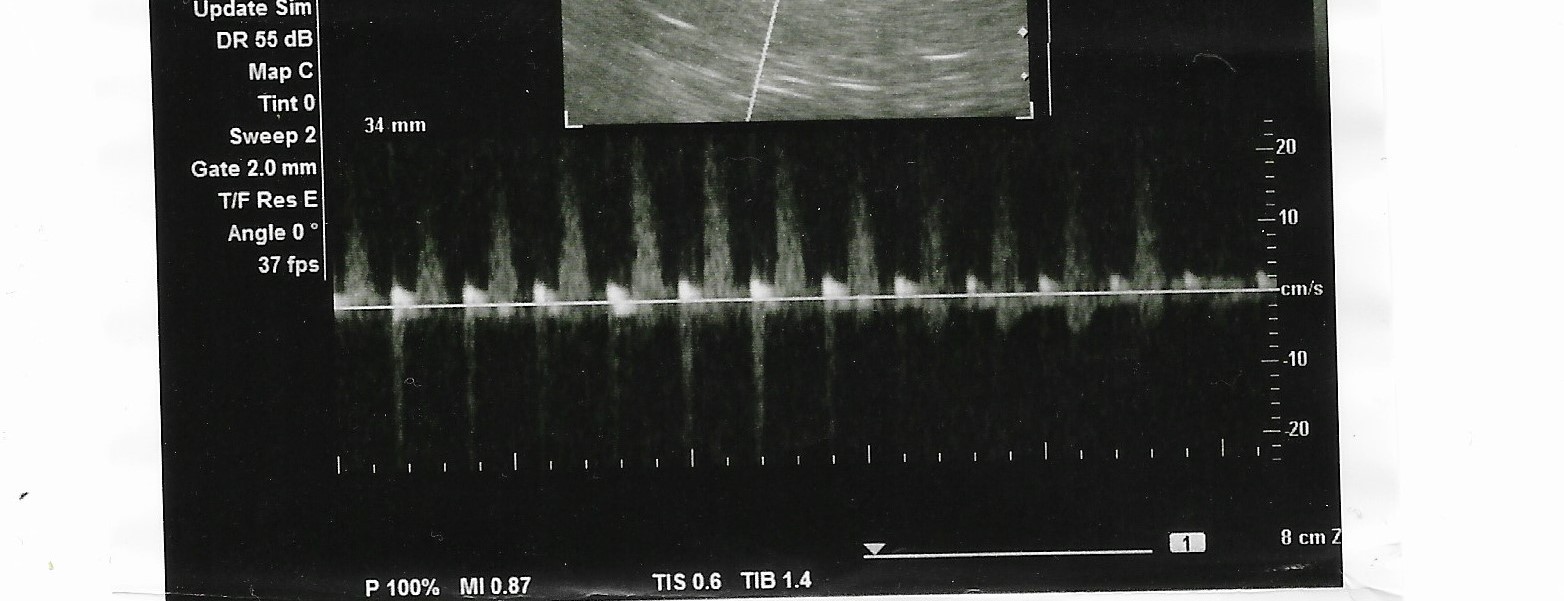
The person asking for assistance mentioned it was a waveform image, but the scan looked more like an audio spectrogram than a raw waveform. I didn’t know for sure what I was looking at so I took to the internet and did some research on ultrasound technologies and found that it was a graphical representation called a spectral Doppler. The image represents the direction and velocity of blood flow within an artery and is generated by analyzing data taken during ultrasound imaging.
During my research I found many videos on YouTube of hospital visits where this type of spectrogram was taken. Many of the videos had recordings of the audio generated by the same machine that generated the image. The audio sounded like white noise that was filtered to de-emphasize certain frequency ranges over time. I downloaded a couple of the videos and found that the spectrogram of the audio was nearly identical to the graphical spectrogram in every video. This gave me a couple ideas for how to synthesize the same type of audio the machine did.
I decided to work “backwards” and tried to figure out how to generate audio that would have a similar spectrogram when analyzed. Rather than taking white noise and filtering it into the shape of the spectrogram, I figured it would be easier to build up that spectrogram by mixing waveforms of different frequencies. I am very inexperienced in DSP, but I remember reading about synthesizing white noise by mixing many different frequencies of sine waves which seemed like a good place to start.
To test the white noise idea I created python script to generate and mix many different frequencies of sine waves using wavetable generators. I picked a range of 1Hz to 4kHz because that was the range of sounds produced by the machines I found in videos. I chose to generate a total of 256 waves because my algorithm was very slow and this count was fairly tolerable to wait for. My initial attempt was less than spectacular.
All of the waves that were generated started at the same phase which produced a scifi-like effect. I randomized the starting phase of each sine wave which got me a little closer to the noise I was looking for.
This sounded more like noise, but had regular patterns in it that reminded me of the sound produced by demodulating a digital radio signal as analog audio. After playing a bit more I found that slightly randomizing the center frequency of each wave produced a nicer noise.
Increasing the number of waves to 1024 improved the quality quite a bit.
I needed to use the spectrogram scan to modulate the sine waves, but the raw scan wasn’t suitable for use without some modification. The original image had legends and a line marking the x-axis which I removed using GIMP. I also increased the brightness and contrast of the image to pull more details out.
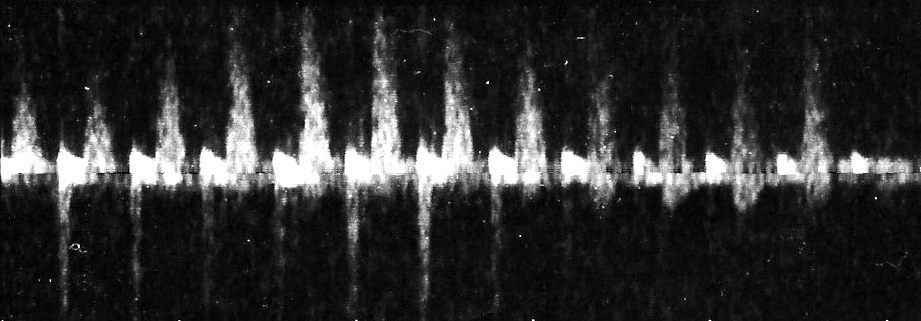
To synthesize audio I mapped each row of pixels in the spectrogram image to a sine wave generator and used the brightness of each pixel to modulate the amplitude of the generator over time. The top row of the image is mapped to the highest frequency while the bottom row is mapped to the lowest. I used the Python library Pillow to read and process the spectrogram image one column of pixels at a time. I also used Pillow to resize the image vertically to allow tweaking of how many wave generators are used.
The script I wrote for testing accepts a count of samples to generate for each column of pixels to set the playback speed. The scan of the spectrogram has 177 pixels between each second marker which calculates out to about 45 audio samples per pixel when using a sample rate of 8kHz (8000 / 177).
The output of the script is somewhat similar to the audio generated by real ultrasound machines, but it sounds more like a “whistle” to my ears than shaped noise. The spectrogram of the output audio looks very promising.
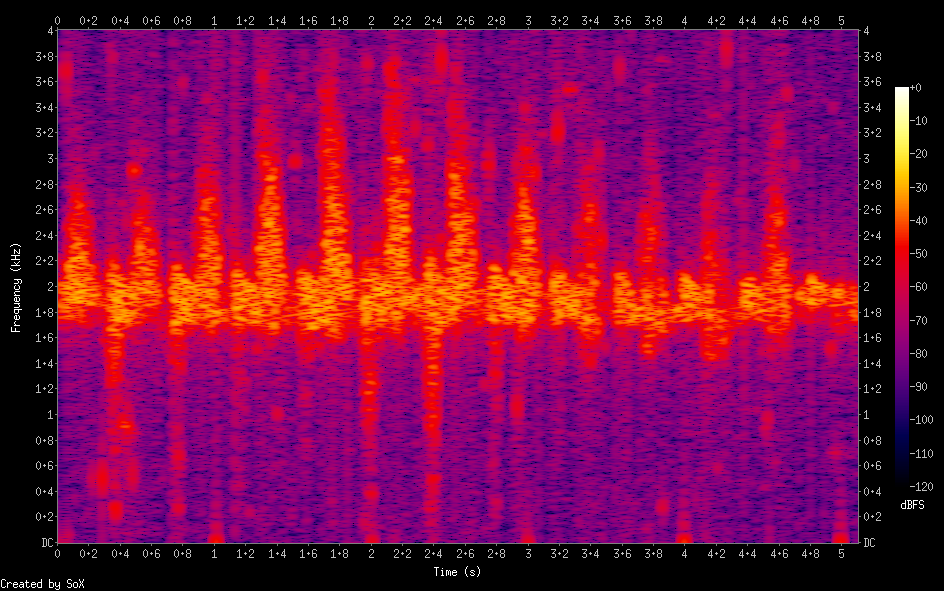
This first attempt is draft quality at best. The audio that is generated is still far from what I’m hearing from ultrasound machines. On top of the audio shortcomings the script is extremely slow and consumes a lot of memory due to the wavetables used for generation. This first attempt is very rough, but it has given me many ideas for improvement.